
Installed utility-scale battery energy storage system (BESS) is expected to cross the 100-GW milestone this year, and yet no two utility-scale BESS installations are exactly alike. A 4-hour, fully integrated AC block LFP shifting 100 MW of Kern County sunshine, a 1-hour tier-2 air-cooled NMC tied to a dusty 5kV pole somewhere in West Nowhere, Texas, BESS-as-fleet-charging, BESS-as-UPS, BESS-as-a-Service … all of them, technically, fall under the umbrella of “utility-scale storage.”
What began as a binary choice between DC-coupled and AC-coupled architectures has fractured into a broad and still-expanding mosaic of hardware configurations, each one a purpose-built prototype running a proprietary controls stack its owner did not write and cannot meaningfully inspect. The utility industry is used to evolving over decades, not months, and the growing pains are painfully evident: you can’t learn from data you can’t see, and you can’t equip operations teams with institutional knowledge that doesn’t yet exist.
COMMENTARY
In the same way the stationary storage development cycle is modeled from its electric vehicle (EV) cousin, control algorithms are modeled from the contracts they serve: written for conservative operations and locked in at commissioning. But unlike EV development, where fleet data directly drives improvement, BESS product development is focused on scale rather than stability. Density, part count and ease of installation are the metrics informing the next product revision, which ships on an 18-month cycle, on a new architecture, with little regard for backwards-compatibility. By the time a systemic issue on today’s installation becomes apparent, the EPC warranty window is closed, the replacement components are no longer being made, and the operator’s only recourse is to open a claim against the OEM or integrator, using the limited historical data their own controls stack produced. Operators in this position find themselves asking a question with no clean answer: how do you build an evidence base for a system you were never given the tools to understand, let alone operate to its full potential?

Amplifying the data gap is a talent gap: BESS engineering requirements extend far beyond the usual power systems to include fire protection, chemical, data science, and software. The teams who originally designed and commissioned these systems mastered one or two of those disciplines in a tangential industry, and the teams now responsible for operating and maintaining them are smaller, geographically diverse, and in many cases are handed the keys to first-generation, distressed assets they had no hand in building.
Coordinating that service, tracking and benchmarking asset performance across sites, and building the operational and institutional knowledge required to manage a growing portfolio: that work falls to a small number of highly intuitive, action-oriented individuals who largely came up in traditional generation. Those fields have genuine, hard-earned maintenance cultures. The challenge is that none of them developed alongside an asset class where the controls hierarchy withholds the very data those quick decisions depend on.
Each year, TWAICE conducts its worldwide BESS Pros Survey. Of the O&M respondents we surveyed, we identified four recurring themes consuming most of their time: immediate incident response, alarm interpretation, evidence gathering for supplier disputes, and chasing resolutions with equipment that may itself be the problem. None of those are portfolio-building activities. Addressing these pain points means acknowledging the shared root cause: limited access to operational data.
50,000 Data Points, One State of Charge
Every commercially available BESS is programmed to calculate and broadcast its state of charge. It does this dutifully and continuously, and it is always confidently wrong. The controls hierarchy producing that number was designed to protect the equipment and the grid, not the owner-operator. Battery state of charge is physically immeasurable, so the system aggregates and estimates, layer-by-layer, discarding lower-level calculations as it goes. At every control board between cell and operator, data is filtered, compressed, processed and then discarded. What surfaces to the operating dashboard is not a measurement, it is the output of a compression stack, or more aptly, a data suppression stack.
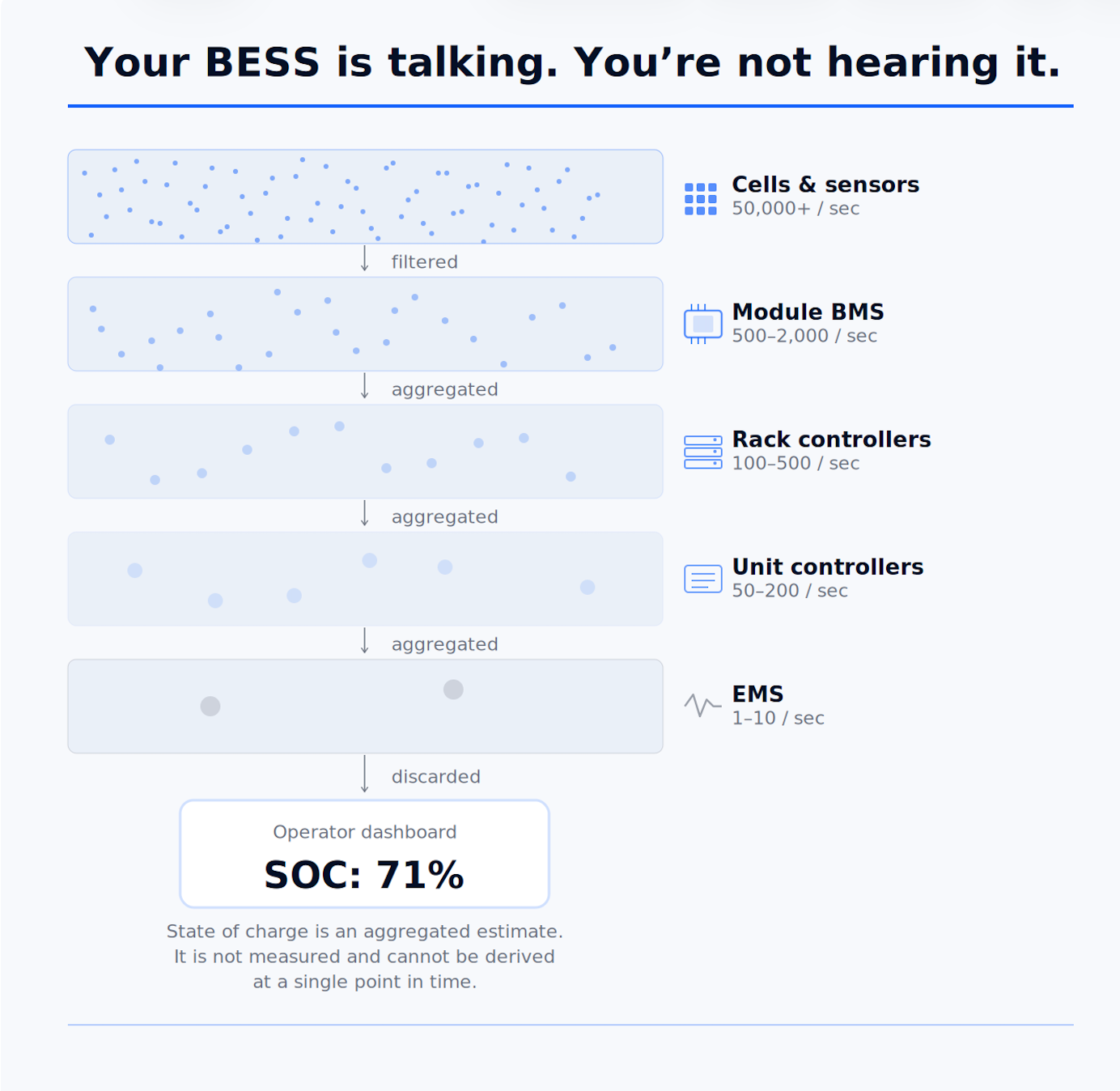
Data suppression is not so much a design flaw as a necessary compromise. A large system easily generates 50,000 data points per second, which must be processed and converted into thousands of unit-level dispatch commands. All of these must be continuously fine-tuned to track a single grid command with sub-second accuracy. That granular process cannot be meaningfully exposed in real time, nor can operators meaningfully intervene, so we accept that the system behaves autonomously. This lightens the cognitive load, but for the controls stack to be essentially un-auditable by human operators is a fundamental flaw that needs an equally fundamental fix: raw, real-time data access. You cannot establish a baseline against a process you cannot observe. You cannot optimize against a baseline you cannot establish.
Yet the underlying factor that creates million-dollar snowflakes is unavoidable: electrochemistry. No two cells behave exactly alike, so each discrete layer of electrical aggregation demands a corresponding layer of monitoring, and each aggregation handler must be purpose-built for safety and fast response. Sensing, yes. But acting takes priority, and logging that enormous volume of realtime data becomes a mere afterthought—left, at best, to legacy industrial historians running aggressive compression algorithms against hard storage limits.
Inside the data stream itself are random bursts of values wrapped with three-letter acronyms denoting the various devices and subsystems. That 50,000-sensor number mentioned earlier actually excludes cell-level data, which can quadruple the overall point count. All of this data flows to a unit or block controller, which nominally reports to and follows the EMS—except when its own protection logic has something to say. The EMS receives that aggregated output and acts on an approximated reality, but the data underneath it all—the thousands of actual sensors feeding these values—are inexpensive, fragile and failure-prone. Despite this, all sensors are treated as authoritative by the hardware, so when a PCS or BMS derates, be it thermal protection, a cell fault, a balancing event—it does not announce why. It just derates. The EMS has to make a split second decision to either compensate on the fly or fail the command. Fifty-thousand data points, one state of charge, and it’s wrong.
While we don’t outright accept it, the current reality is that large-scale BESS exceeds available computing power, so we rely on the system to self-protect, we take fractional intermittent outage as the cost of scale, and ironically, our best solution to failure-by-complexity is adding more BESS.
The Unintended Consequences of Sizing Like Solar
Folks moving into stationary storage from PV brought along the good instinct to overbuild at COD, but also carried over the intense commercial pressure to achieve that COD before peak season. Those two forces together make incomplete COD a routine outcome with lifelong consequences. The short-term thinking makes sense: once the system is functional enough to dispatch at nameplate, the trading desk is wired in and the site begins to cycle. EPC demobilizes down to a skeleton crew focused on the last few obvious punch list items. Rigorous data-backed QA/QC work that catches subtle issues is rarely performed, and over the first few months the punch list actually grows. A 2024 white paper co-authored by EPRI, TWAICE, and PNNL examined 26 classified failure incidents and found that only 11% were attributed to cell manufacturing. BOS and controls issues dominated, and 72% of failures occurred between construction and the first two years of operation. The report also noted that several of these failures started small and cascaded into major damage, precisely because monitoring and communications were not yet online to pick up on the telltale signals and provide early warning. The data was there, the oversight wasn’t.
But that monitoring isn’t limited to component failure. Under normal operations, the BMS enforces voltage protection bands at both ends of the SoC range to keep cells in a predictable, linear operating window. In that middle range, simple coulomb counting (summing current over time) can approximate the system SOC. However, coulomb counting relies on those same inexpensive sensors, and requires frequent calibration, which means driving the system down into the lower voltage range its controls logic was designed to avoid. Without that calibration, BMS will mistakenly drive a rack past its limits until a self-protection cascade kicks in, automatically dragging larger portions of the system offline. Operators watching this in real-time have limited visibility: they can see the power output drop and a cascade of alerts popping up, but they cannot pinpoint the root cause or meaningfully intervene. They file a service claim and, in the meantime, underbid the system.
Service agreements and warranties are written against nameplate, not against actual commissioned capacity. The clock for repairs and liquidated damages often begins when the ticket is filed, not when the failure occurred. In the most extreme cases, several containers can sit offline, and as long as the overbuild provides sufficient capacity to meet nameplate, there is no damage to claim. When controls architecture masks underperformance and contract structure removes urgency, the commercial reality is that of good faith effort. Lean O&M teams rely on lean vendor support. Corrective maintenance is a targeted effort keep the system within contract bounds in the short term…nevermind the overbuild. But short-term action has long-term financial impact. Capacity fade is seldom addressed, and the go-to solution of “add more BESS” is using capital to address an operational issue: BESS operators are, in many ways, outside observers of their own systems with limited ability to reconfigure controls. On the ground, maintenance teams are triage surgeons addressing the most obvious issues without the ability to diagnose underlying causes. Both teams are focused on commercial impact; neither team has the bandwidth to build tools and workflows aimed at scaling.
What Independent Data Changes
OEM monitoring software cannot provide an independent view of this because it is produced by the same controls hierarchy. It surfaces the aggregated output of the BMS and EMS layers, formatted for the manufacturer’s purposes. Owner-operators are vendor-locked to that view unless they have an independent data layer.
During commissioning of an InterEnergy site, TWAICE’s analytics platform captured live, granular data during the commissioning process before the system ever dispatched commercially. A persistent performance shortfall across several pieces of equipment was successfully traced back to a non-operational module. The fix was a warranty replacement, resolved before the site went live. Without that depth of analysis during commissioning, the same issue enters operations as an unexplained performance gap the operator is responsible for proving, retroactively, against a warranty clock that started the day the ticket was filed. What could have been months of analysis, engineering overhead and iterative troubleshooting across multiple teams was instead a simple same-day swap by a single technician.
Operating teams care most about preserving long-term asset value and maximizing performance. They need systems and processes that flag issues proactively to allow for maintenance to be scheduled and carried out efficiently. Temperature drift on one side of a container. A rack cycling at half the rate of its neighbors. Subtle underperformance seldom triggers an equipment alarm, because the controls stack was never built to care about any of this. BMS is a simple board with roughly the processing power of a $4 Raspberry Pi Pico, or a disposable e-cigarette. What independent analytics changes is the ratio of eyes to data points. A purpose-built cloud-analytics platform that normalizes data, proactively detects issues, prioritizes recommendations for corrective maintenance replaces hours of manual workflows. Integrating that platform with existing ticketing and reporting systems, dashboards and revenue models allows a single engineer to manage gigawatts of BESS from a single screen. The vendor controls stack cannot do this. It was never intended to.
The Practical Return
The data problems described here are not engineering failures. The controls stack is doing exactly what it was designed to do. The problem is that what it was designed to do has never included giving operators an independent view of what is actually happening inside their assets. That view has to come from outside the vendor stack, and it has to be built for the operator, not for the equipment.
The industry is adding gigawatts of storage to a grid that desperately needs reliable, dispatchable power. The teams responsible for ensuring that reliability are not getting proportionally larger. What scales is the data layer. A team that can see across a portfolio in real time, that has an evidentiary record that predates any warranty dispute, that is alerted to a developing fault before it becomes an outage event, is not working harder than the team that doesn’t. They are working with better tools.
—Chris Pickett is a Senior Solutions Engineer at TWAICE with extensive experience guiding energy storage projects from design through deployment.















