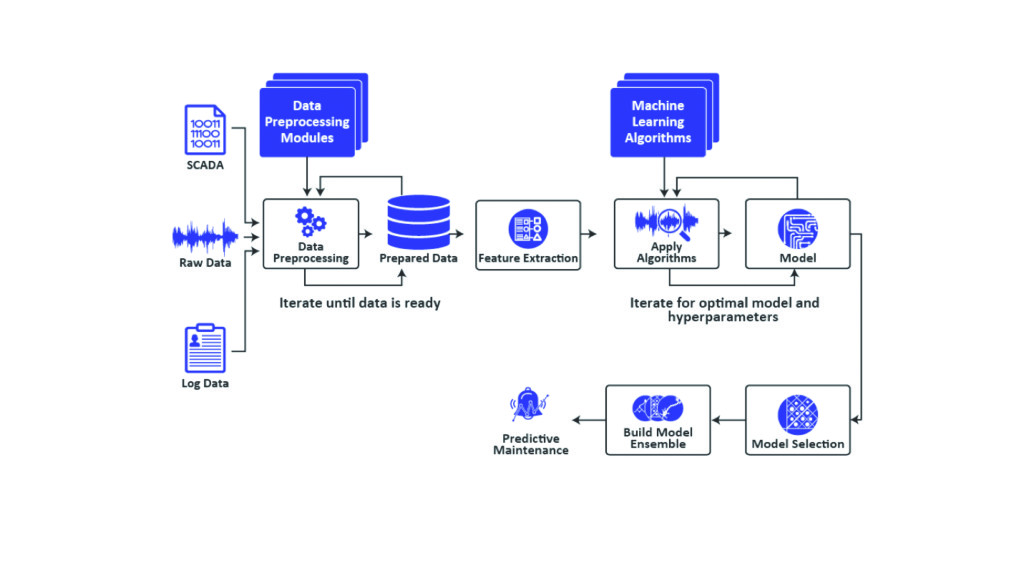
Artificial intelligence and machine learning aren’t just fictional pieces of futuristic Hollywood movies. Power plants can deploy these innovative technologies today to more accurately predict the condition of assets and schedule appropriate maintenance to correct equipment problems before failure.
Although the new administration in Washington has reversed the “war on coal,” long-term trends in the U.S. are not promising. Most coal-fired capacity was built between 1950 and 1990, and the average coal plant is about 42 years old. With plant retirements expected to continue in 2018 and beyond, investment in new plants has come to a standstill.
The confluence of regulatory issues and alternative energy sources is well known. Because revenue growth is a function of fluctuations in market-based commodity pricing, one of the few remaining opportunities for meaningful bottom-line growth is improving operational efficiencies. Applying Industry 4.0 and machine learning for predictive maintenance could help keep the coal industry financially viable.
The Current State of Maintenance
Coal plant maintenance is often based on a mix of reactive, preventive, and predictive techniques. In general, the closer to an event that a failure is detected, the more expensive the cost of repair (Figure 1).
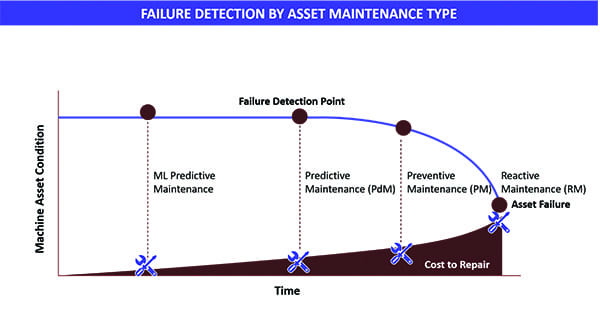 |
| 1. Early detection saves time and money. Predictive maintenance using machine learning (ML) can help detect problems long before traditional maintenance techniques typically identify them. Courtesy: Presenso |
Reactive Maintenance (RM). Given the financial pressures facing the industry, it is not surprising that the run-to-failure mentality is still prevalent. With shrinking operations and maintenance budgets, reactive maintenance offers one singular advantage: no upfront costs. However common in the industry, waiting for failure to occur is not cost-effective in the long-term. That is because once an asset fails, the cost to repair increases exponentially.
First, failure in a single piece of equipment can lead to a partial or even full plant shutdown, resulting in lost revenue. At the same time, the plant must continue to pay fixed costs during the shutdown. Second, during an unplanned shutdown, there is increased pressure for a quick fix. Sometimes the pressure on the repair crew leads to human error. Furthermore, without detailed knowledge of why the failure occurred, repair crews sometimes rely on trial-and-error techniques to identify the problem. Finally, RM is the least cost-effective because the plant does not benefit from any advanced planning. In many cases, the emergency repair requires the removal of a crew from another maintenance task while waiting for parts and equipment to reach the site.
Preventive Maintenance (PM). Preventive maintenance is a necessary component in any maintenance strategy. Typically, PM is performed based on a time schedule that is provided by the equipment manufacturer or by reliability technicians. Some plants use mean-time-before-failure (MTBF) estimates to determine the frequency of PM needed. This is based on the average time between failure events for the asset type. The challenge in using MTBF for scheduling is that it is based on historical averages and does not take into consideration machine-specific condition and failure factors.
Furthermore, although the theory of PM is logical, there are many instances where maintenance work itself results in asset degradation. Common human errors include over lubrication or inadvertently damaging the equipment during the maintenance tasks. In a study of fossil-fueled power plants, a majority of forced maintenance outages occurred less than a week after a planned maintenance outage (1,772 of 3,146 unplanned maintenance outages reviewed occurred shortly after an initial outage). The conclusion was that “in 56% of the cases, unplanned maintenance outages were caused by errors committed during a recent maintenance outage.”
Predictive Maintenance (PdM). Historically, the industry’s approach to predictive maintenance has been progressive. Different techniques are used to monitor the health of a plant asset including vibration monitoring, oil residue analysis, and thermal imaging. The advantage of PdM is that it has been used to identify machine degradation or potential asset failure earlier than PM and RM.
However, there are three major factors that limit the value of PdM. First, supervisory control and data acquisition (SCADA)-based process monitoring using programmable logic controller (PLC) data relies on human-established and other predefined rules. For instance, an alert may be generated if the temperature of a machine exceeds an upper control threshold of 40 degrees or if it is less than a lower threshold of 20 degrees. Although overheating is important to measure, this information does not provide a complete analysis of why the equipment overheated. Furthermore, SCADA systems typically monitor control breaches, but do not analyze anomalous behavior in the data while it is still within the boundaries of its statistical process control limits. In the illustration presented in Figure 2, an anomalous pattern of sensor behavior is shown. However, because it occurs within the control limits, no alerts are generated.
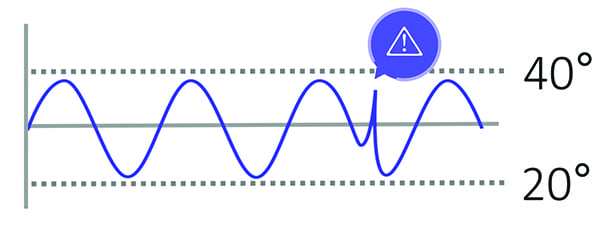 |
| 2. Abnormal, but not out of bounds. In the example shown here, a temperature band of 20C to 40C is considered acceptable. Machine learning algorithms could spot unusual fluctuations within that band that might be overlooked by operators witnessing variations in real time. Courtesy: Presenso |
An additional challenge that limits the utilization of PdM techniques is that they are typically based on an analysis of a single data source and do not provide a holistic view of asset health. For instance, vibration analysis or thermal imaging can be used to predict specific changes in asset behavior, but do not provide a comprehensive view of the evolving degradation.
Machine Learning for Predictive Maintenance
Until recently, machine learning was a discipline mostly confined to academia. Over the last couple of years, there has been a rapid commercialization of artificial intelligence (AI) and “Big Data,” especially in the financial services and high-tech sectors. With the emergence of Industry 4.0, the application of machine learning to the industrial sector is now underway.
Machine learning is used to analyze Big Data generated from plant sensors and to detect abnormal data patterns. After the data is extracted, whether it be from a superheater tube, crusher, surface condenser, or some other component, the data is then analyzed using advanced AI algorithms. These algorithms look for anomalous behavior and patterns of anomalous behavior that are indicative of evolving degradation or failure. Solutions based on machine learning provide root cause analysis (RCA) that is used by repair crews to isolate the underlying failure and time-to-failure (TTF) estimates.
There are two types of machine learning methodologies: supervised and unsupervised. With supervised machine learning, the algorithm is “trained” using human guidance and labels of abnormal and normal machine conditions. When new data is analyzed by the algorithm, it can then classify the data as failure indicative, if it recognizes the pattern from its training.
With unsupervised machine learning, the algorithm does not need to be trained using the physical blueprints or knowledge about the process itself. Furthermore, with cloud-based unsupervised machine learning, plant reliability and maintenance staff are alerted to asset degradation and failure without the need for internal Big Data engineers or data scientists to interpret the data. This is an important consideration for coal plants that lack the resources to develop internal competencies in Big Data and machine learning.
The difference between supervised and unsupervised machine learning is not theoretical. With unsupervised machine learning, the machine model generation and then the continuous maintenance of it are automated. This fact has a crucial impact on solution deployment. The underlying differences ultimately impact both operational metrics and return on investment.
In practice, there are significant resources required to train the supervised model. The so-called “digital twin,” which is based on the supervised machine-learning model, relies on a low-level understanding of the actual physical process happening in the machine–physical modeling. In this case, a virtual clone of the original machinery is created using the blueprints of the physical machine. If there are modifications made to the machine in the field, these need to be updated and used in the twin as well. A deviation between the physical machine and the virtual clone will diminish the accuracy and utility of the digital twin.
With unsupervised machine learning, the algorithm needs no knowledge of the physical layout of the machine or its mechanical processes. In fact, the algorithm is agnostic to machine and sensor type. This eliminates the need for a facility’s process engineers and Big Data scientists to train the algorithm.
Furthermore, with automated unsupervised machine learning, the algorithmic model is self-learning and self-maintaining, and therefore it can be applied to various types of machines from various vendors.
Industrial Analytics in Today’s Coal Plant
Given the age of the average coal plant and the uncertain regulatory environment, there is a hesitancy on the part of coal plants to commit significant resources to Industry 4.0 upgrades. In an environment where plants are closing and incremental investments are at a standstill, the coal industry has demonstrated little interest in industrial analytics for PdM.
Part of the reason can be attributed to the fact that the most-well-known solution on the market is the digital twin, which requires an investment in industrial internet of things (IIoT) infrastructure and internal plant resources to build the virtual clone.
However, the assumption that costly IIoT infrastructure is a prerequisite for industrial analytics for PdM is no longer valid. With the emergence of unsupervised machine learning as an alternative to the digital twin, the coal industry can now access real-time RCA and TTF information without the need for expensive infrastructure investments. Given the industry’s aging asset base, unsupervised machine learning can be used to scale PdM solutions and increase plant asset life. ■
—Eitan Vesely is CEO of Presenso.